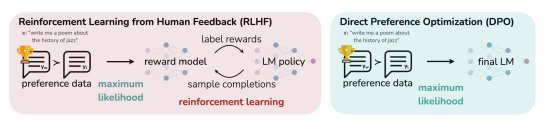
원문 https://arxiv.org/abs/2503.18908 FFN Fusion: Rethinking Sequential Computation in Large Language ModelsWe introduce FFN Fusion, an architectural optimization technique that reduces sequential computation in large language models by identifying and exploiting natural opportunities for parallelization. Our key insight is that sequences of Feed-Forward Networkarxiv.org Abstract대규모 언어 모델(LLM)의 확장..