원문
https://arxiv.org/abs/2503.18908
FFN Fusion: Rethinking Sequential Computation in Large Language Models
We introduce FFN Fusion, an architectural optimization technique that reduces sequential computation in large language models by identifying and exploiting natural opportunities for parallelization. Our key insight is that sequences of Feed-Forward Network
arxiv.org
Abstract
대규모 언어 모델(LLM)의 확장으로 인해 컴퓨팅 자원의 부담이 커지고 있으며, 이를 완화하기 위한 최적화 기술이 필요함. 기존 방법론(양자화, 가지치기, MoE)의 한계를 극복하기 위해 새로운 접근 방식이 요구됨.
기존 방법론의 한계
- 양자화(Quantization): 정밀도 손실 발생 가능
- 가지치기(Pruning): 비정형 가지치기의 효율성 한계
- MoE (Mixture-of-Experts): 작은 배치 크기에서 비효율적, GPU 활용률 문제
제안 방법 개요
FFN Fusion은 LLM의 순차적 연산을 줄이기 위해 특정 어텐션 레이어 제거 후 연속적인 FFN(Feed-Forward Network) 레이어를 병렬화하는 기법임. 이를 통해 모델의 성능을 유지하면서 추론 속도를 개선함.

Contribution & Methods
본 연구에서는 FFN Fusion을 적용할 최적의 위치를 식별하기 위해 모델 내 블록 간 의존성을 정량적으로 분석함. 이를 위해 코사인 거리를 활용하여 특정 블록이 다른 블록에 미치는 영향을 평가함.

우선, 블록 간 의존성을 측정하기 위해 hj(X)는 블록 가 입력 에 기여하는 변화량을, ~hi(X)는 블록 i를 제거한 경우 블록 j가 입력 에 기여하는 변화량을 나타냄. 이를 통해 블록 i의 존재 여부가 블록 j에 미치는 영향을 정량적으로 측정할 수 있음

- 값이 작음 (파란색) → 블록 i 제거 후에도 블록 j 변화가 적음 → 낮은 의존성 → 병렬 연산 가능성↑
- 값이 큼 (빨간색) → 블록 i 제거 시 블록 j 변화 큼 → 강한 의존성 → 순차 처리 필요
이 섹션에서는 FFN Fusion 기법을 사용하여 Llama-405B 모델을 더 컴팩트한 Ultra-253B-Base 모델로 변환하는 방법을 설명.
FFN Fusion
- Llama 3.1 -405B 모델에서 연속적인 49개의 FFN Layer를 4개의 병렬 Fusion Layer 로 융합 [66, 73], [74, 85], [86, 100], [101, 114], [115]
- 마지막 FFN Layer의 경우는 출력층이므로 그대로 유지.
추가 훈련 (KD & CPT):
- 지식 증류(Knowledge Distillation)를 활용하여 여러 컨텍스트 길이에서 점진적으로 성능을 회복.
- 지속적 사전훈련(Continual PreTraining )을 통해 추가 최적화 진행.
효율성 개선
- 1.71배 빠른 사용자 지연 시간 및 메모리 절감
- H100 GPU에서 단일 노드로 작동 가능
- 추론 속도 개선 (최대 202 tokens/s with speculative decoding)


블록 병렬화
본 논문은 한 발자국 더 나아가 transformer 블록도 병렬화를 시도함.
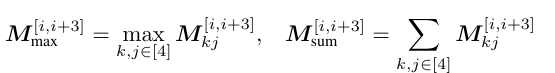
핵심은 블록간 Mmax 와 Mmin 은 블록 간의 상호의존성이며, 위 수식대로 각 블록I와 블록J의 상관성 히트맵을 제작함.

기존 FFM Fusion보다는 블록간 상관성이 더욱 높음을 확인할 수 있음.

- 처음 및 두번째 시퀸스를 병렬화 하는 것은 약간만의 MMLU 감소가 일어나지만, 세번째 시퀸스 이상을 추가하게 되면 급격하게 MMLU가 감소함을 볼 수 있음.
- 이는 전체 블록 병렬화가 FFN 융합보다 더 도전적임을 시사함
Additional Experiential Content
Removing FFNs vs. FFN Fusion
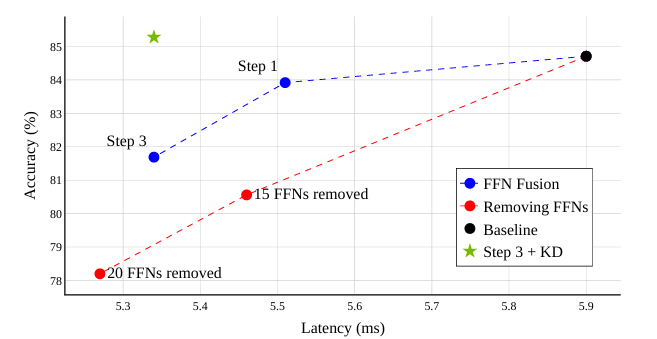
FFN 제거와 FFN 융합을 비교한 결과, 대규모 FFN 제거는 정확도 저하를 초래하지만, FFN 융합은 표현 용량을 유지하면서 latency을 줄이는 효과가 있음. 중요도가 낮은 FFN을 제거하는 방식(Puzzle 블록 중요도 점수 활용)과 융합 방식(단일 병렬 모듈 유지)을 비교한 실험에서, FFN Fusion이 지연 시간을 개선하면서도 정확도 저하를 최소화하는 것으로 나타남.
TheFinal FFN in Each Sequence is Sensitive to Fusion
49B 모델에서는 긴 FFN 시퀀스의 마지막 레이어를 융합하면 성능이 크게 떨어짐. 특히, 마지막 FFN 레이어 (51, 70)을 포함하면 정확도가 더 감소하는데, 이 레이어들이 모델 표현에 중요한 역할을 하기 때문.
표 3에서 첫 번째 실험은 각각의 시퀀스를 따로 융합하는 방식([42,50] vs. [43,51], [53,69] vs. [54,70])을 비교했는데, 레이어 70이 매우 큰 영향을 받음. 두 번째 실험은 두 시퀀스를 동시에 융합하였으나, 마지막 FFN을 포함하면 성능이 더 떨어짐.

결론
FFN Fusion은 LLM의 순차적 계산을 병렬화하는 새로운 최적화 기법으로, 모델 능력 저하 없이 효율성을 크게 향상시킴.
Llama-3.1-405B 기반의 Ultra-253B-Base 모델은 FFN 융합을 통해 추론 속도 1.71배 향상 및 토큰당 비용 35배 절감을 달성했으며, 원래 모델과 동등하거나 능가하는 성능을 보였음.
이는 FFN 레이어의 낮은 상호 의존성 덕분이며, 향후 모델 해석 및 새로운 병렬화 아키텍처 설계에 대한 가능성을 제시.
결론적으로, FFN 융합은 LLM의 효율성과 성능을 동시에 혁신할 수 있는 중요한 기술임.