반응형
0. Abstract
- 대규모 텍스트 기반 이미지 합성 모델의 발전
- 관련 기술에 대한 수요로 주목받고 있으나, 텍스트 프롬프트의 작은 변화에도 결과가 크게 달라지는 문제 발생
- 기존 이미지 편집 방법의 한계
- 사용자가 편집 영역을 직접 마스크해야 하는 번거로움 존재 (Inpainting 기법)
- 또한 편집되는 원본의 Attention 구조를 받아오지 못해 실제 결과랑 이질감이 발생
- 마스크 내부의 구조적 정보를 효과적으로 활용하지 못함
- 사용자가 편집 영역을 직접 마스크해야 하는 번거로움 존재 (Inpainting 기법)
- 주장하는 방법
- prompt-to-prompt 로 직관적으로 이미지를 편집할 수 있는 새로운 방법 개발
1. Introdution

-
그림 1은 Prompt-to-Prompt 편집 기능의 다양성을 보여주는 예시 그림
-
사용자는 텍스트 프롬프트만으로 이미지 픽셀 공간에 대한 어떠한 정보 없이 diffusion 모델의 cross-attention 메커니즘을 통해 다양한 편집을 수행
- crowded를 제거하거나, car를 bycicle로 변경하는 등 단일 토큰값을 변경하여도 이미지의 일관성은 해치지 않으면서 토큰에 해당되는 이미지로 자연스럽게 대체.
2. Related research

이미지 변환 과정은 그림 2의 과정을 통해 변환이 이루어짐.
Text-to-Image Cross-Attention
- Pixel features
- Diffusion 모델에서 이미지(또는 노이즈 상태)의 임베딩을 추출한 결과.
- Pixel Queries
- 이미지 특징 ϕ(zt)가 학습된 linear projection Q를 거쳐 Query 매트릭스 Q 로 프로젝션
- Tokens Keys (from Prompt)
- 텍스트 프롬프트에서 추출된 textual embedding은 학습된 linear projection K를 통해 Key 매트릭스 K 로 프로젝션
- Attention maps
- Query Q와 Key K를 사용하여 Attention 맵 Mt 가 계산. 이를 통해 이미지의 각 픽셀이 텍스트 토큰 각각에 얼마나 detection 됨을 확인.
- Tokens Values (from Prompt)
- textual embedding과 학습된 linear projection V를 통해 Value 매트릭스 V 로 프로젝션됨
- Output
- Attention 맵 M 과 Value V 를 곱해 cross-attention의 결과인 ϕ(zt) 를 얻음
Cross-Attention-Control
- Word Swap
- 프롬프트에서 특정 단어를 교체할 때, 원본 이미지의 Attention 맵 Mt를 주입하여 대상 이미지의 맵 Mt∗를 덮어씀
- 이를 통해 원본 이미지의 spatial layout을 보존하면서도 교체된 단어만 반영
- Adding a New Phrase
- 새로운 구문을 추가할 때, 변경되지 않은 부분에 해당하는 맵만 원본에서 주입
- 원본 이미지의 세부 사항을 유지하면서도 새로운 내용을 추가할
- Attention Re-weighting
- 특정 단어에 해당하는 Attention 맵의 가중치를 재조정하여, 해당 단어의 의미적 효과를 강화하거나 약화
- 새로운 가중치가 적용된 Attention 맵 Mt^를 사용해 이미지 생성
3. Method

- pixel-word relation
- 그림 3의 이미지 처럼 pixel은 자신을 설명하는 단어들에 더 많은 attention을 기울임
- 이를 통해 생성된 이미지의 시각적 요소와 텍스트 설명 간의 연결을 보여줌
- Attention map 시각화
- 그림의 윗부분은 프롬프트에 있는 각 단어에 대한 평균 attention mask를 보여줌
- 아래쪽 행 "bear"와 "bird"라는 단어에 대한 attention map을 다양한 diffusion step에서 보여줌 이를 통해 diffusion 과정의 초기 단계에서 이미지 구조가 어떻게 결정되는지 확인 가
다만 위 과정은 Cross-attention 과정에서 중첩되는 영역을 통해 자연스러운 conversion을 유도하는 것이지, 변경되는 프롬프트가 사용자의 의도에 맞게끔 그려진다는 보장은 없음. 이를 보완 하기위에 그림 2의 Cross-Attention-Control 의 방법인 attention injection을 추가.

- 좌측은 attention injection을 전혀 하지않았고, 우로 갈수록 가장 높은 강도의 attention injection 주입.
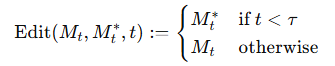
- 초기 단계( t < τ )
- 새로운 프롬프트의 Cross-Attention 맵 Mt를 사용함으로써, 이미지의 전반적인 구성이 새 프롬프트에 맞춰지도록 유도.
- 예시로 “car”를 “bicycle”로 바꾸는 경우, 초반에 새 토큰(“bicycle”)이 지배적으로 반영되어 전체적인 형태가 바뀜.
- 후반 단계( t ≥ τ )
- 원본 프롬프트의 Cross-Attention 맵 Mt를 다시 주입하여, 원본 이미지가 가진 디테일(재질, 색감 등)이나 구조 일부를 되살리거나 유지.
위와 같은 과정을 통해 파라미터 를 조절하여 원하는 강도의 attention injection을 유지할 수있음.
4. Limitation
- Inversion 과정의 왜곡
- 실제 이미지를 편집하기 위해 diffusion 모델에 넣을 초기 노이즈 벡터를 찾는 inversion 과정에서 일부 테스트 이미지에서 눈에 띄는 왜곡이 발생할 수 있음.
- 이 과정에서 이미지 품질이 저하될 수 있음.
- 프롬프트 생성의 어려움
- 복잡한 구성의 이미지에 대해 inversion에 필요한 적절한 프롬프트를 생성하는 것이 어려움.
- 사용자가 원하는 이미지를 정확히 설명하는 텍스트 프롬프트를 만드는 것이 쉬운 일이 아님.
- 낮은 해상도의 Attention 맵
- 현재 사용되는 Attention 맵의 해상도가 낮아 정밀한 로컬 편집에 한계가 있음.
- Cross-Attention이 네트워크의 bottleneck에 위치하여 공간적 해상도가 제한됨.
- 객체 이동의 어려움
- 현재 방법으로는 이미지 내 객체를 공간적으로 이동시키는 것이 불가능함.
- 예를 들어, 특정 객체를 다른 위치로 옮기거나 객체 간 상대적 위치를 변경하는 것이 어려움.