우아한형제들이 주관하는 테크컨퍼런스인 WOOWACON 2024에 참여했습니다!
WOOWACON 2024
한 번의 배달을 위해 필요한 모든 기술들
2024.woowacon.com
운이 좋은지 나쁜지 모르겠지만 이번 컨퍼런스에는 참여형 세션인 이그나이트 세션이 있었는데요, 설마 되겠어? 하는 마음으로 별 다른 준비없이 발표자 신청을 했다가 당선이 되버려서 부랴부랴 발표준비를 한 기억이 있네요 ㅎㅎ;;
우리나라를 대표하는 IT기업에서 진행하는 컨퍼런스인만큼, 다양한 개발자분들이 다양한 세션을 준비해 주셨습니다. 그중 최근에 사이드 프로젝트로 진행하고 있는 누구나데이터 - text to query 변환 챗봇을 열심히 개발하고 있는데요, 관련해서 부족하지만 저의 인사이트를 담은 게시글을 작성하기도 하였습니다. 그래서 아래 소개해줄 "물어보새" 세션이 정말 반가웠고, 정말 많은 도움이 되는 내용이였습니다.
https://wzacorn.tistory.com/102
랭체인을 사용하여 나만의 LLM 구축하기(1)
안녕하세요 민윤홍입니다. 정말.. 정말 오랜만에 블로그 포스트를 하게 되었습니다!사실 블로그 포스트에 손을 뗀지는 조금 오래 되긴 하였지만, 이번에 카카오임팩트에서 진행하는 누구나데
wzacorn.tistory.com
물어보새를 듣고, 저에게 인사이트가 되는 내용들을 정리해보고자 합니다.
1. 물어보새가 뭔가요?
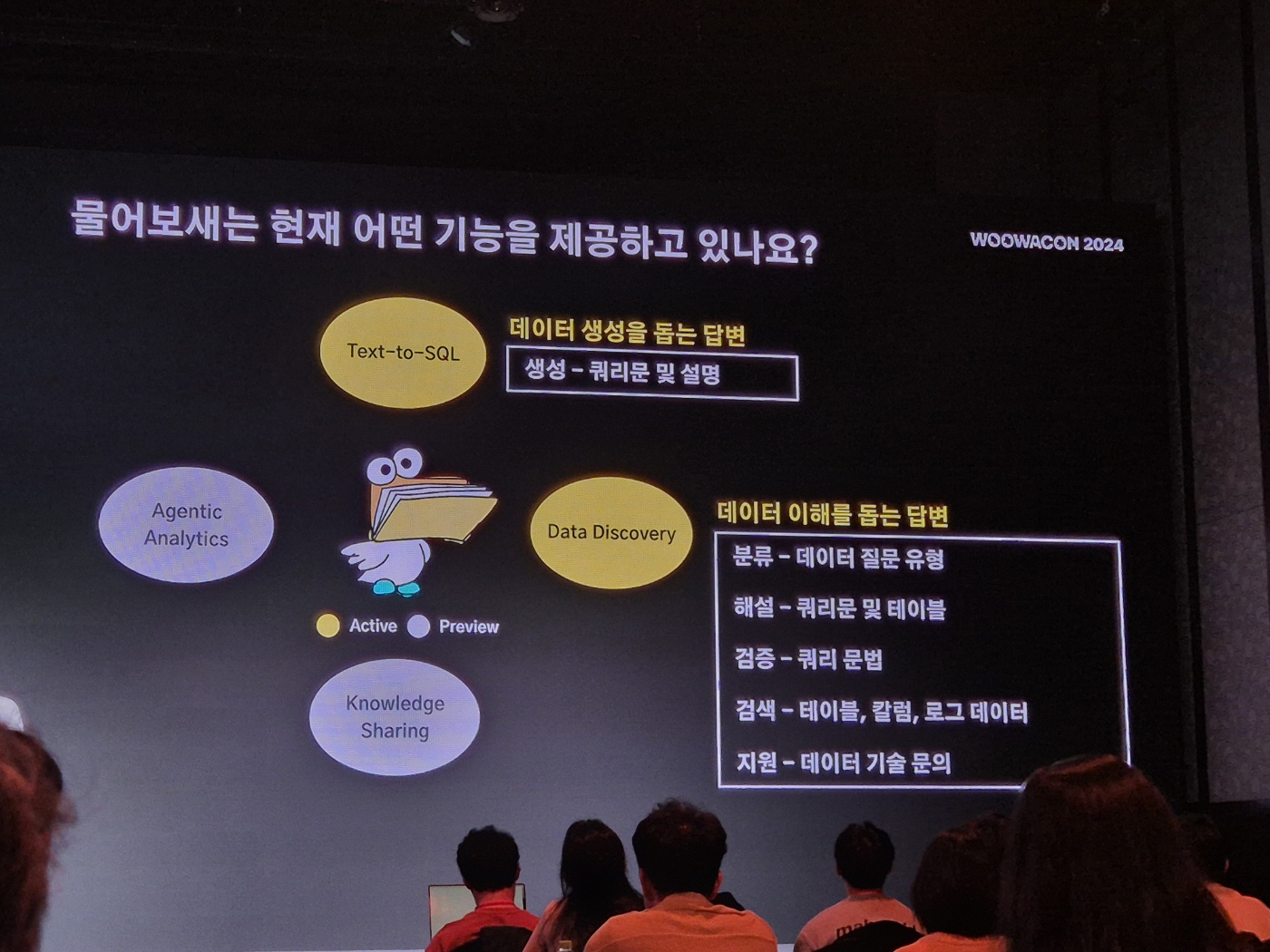
물어보새는 우아한형제들 내부에서 사용하는 슬랙 봇으로, 데이터 분석과 데이터 이해를 돕기 위한 답변을 챗봇 형태로 제공해주고 있습니다. 아래의 사진처럼 2024년 10월 10일 기준 1인별 주류,. 면, 커피 메뉴 음식배달 주문수와 전체 음식 배달 주문수 대비 비율 알려줘라는 프롬프트를 작성하면 아래와 같은 쿼리문이 나오는 것입니다.

인사이트
1. 다중 VectorDB를 두어 목적을 분리할것.

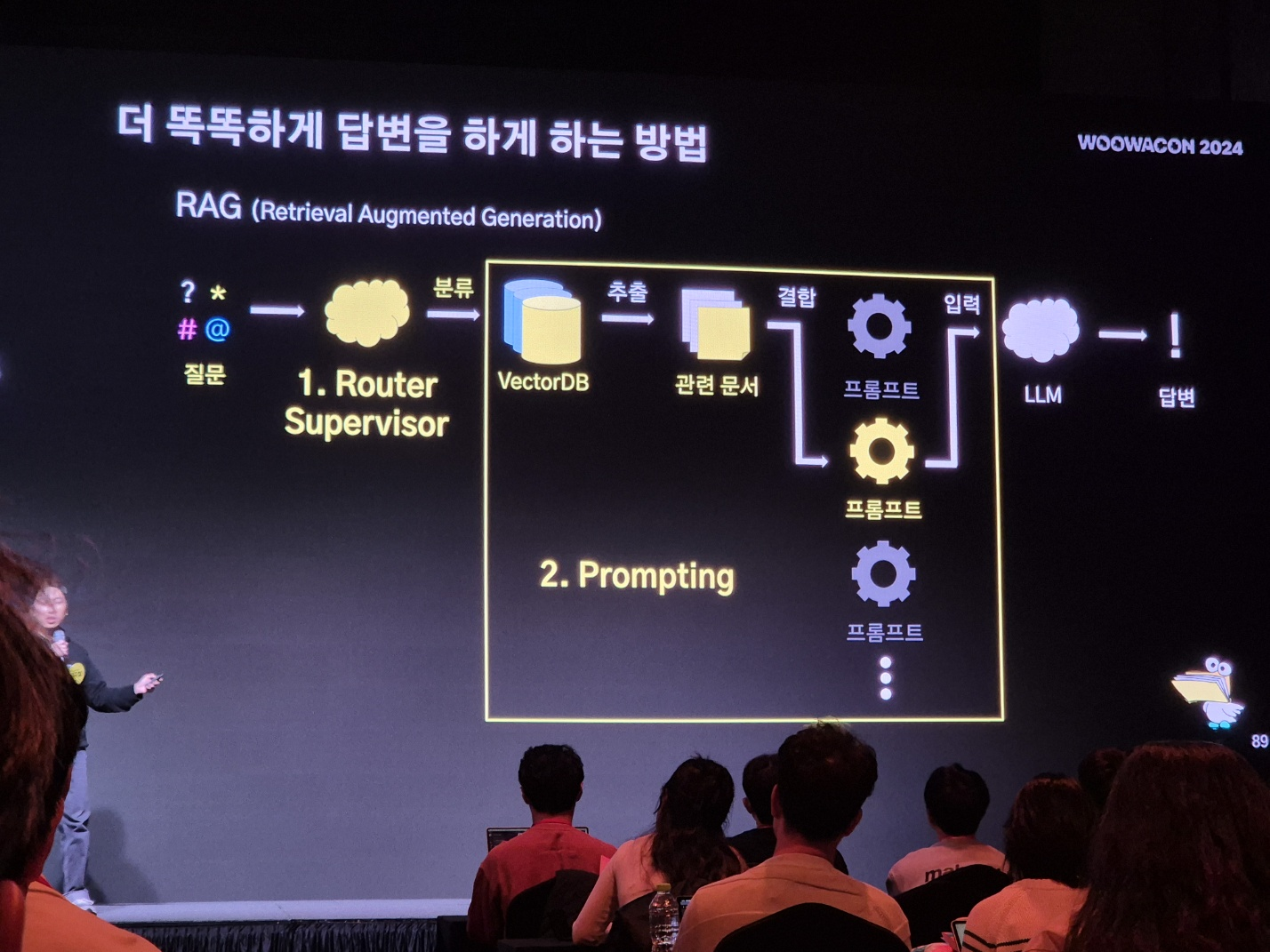
chatgpt와 같은 공개된 LLM이 사내 DB를 학습한 상황이라면, 이는 심각한 보안 문제로 이어질 수 있습니다. 공개하고 싶지 않은 사내 정보를 LLM에 전달하려면 API 형태로 LLM을 호출하고, RAG (Retrieval Augmented Generation) 방식을 통해 필요한 데이터만을 안전하게 제공해야 합니다.
여기서 물어보새는 다음과 같은 구조로 데이터를 처리합니다:
- 사용자가 질문을 입력하면, 질문에 맞는 관련 정보를 찾기 위해 VectorDB에서 검색이 이루어집니다.
- 검색 결과로 얻어진 관련 문서들이 추출되고, LLM이 이해할 수 있도록 프롬프트로 결합됩니다.
- 생성된 프롬프트는 LLM으로 전달되며, LLM은 문서 기반으로 적절한 답변을 제공합니다.
예를 들어, 사용자가 "어제 음식 배달 주문수 알려줘"라는 질문을 하면, A 테이블의 칼럼을 사용해 필요한 쿼리문을 자동으로 작성해주고, 이를 통해 원하는 데이터를 안전하게 조회할 수 있도록 합니다.
여기서 정말로 특이한 점이 LLM에게 전달하고 싶은 정보를 목적에 맞게 분리하여 다중 VectorDB를 구성하였고, 각 VectorDB는 서로 다른 내용과 역할을 담당하고 있어, 필요한 정보만을 선택적으로 LLM에게 전달시킵니다. 우아한형제들 개발자분들은 아래와 같이 5가지의 목적으로 분류하고, VectorDB를 구축하였습니다.

- 테이블 DDL : DB테이블 구조를 정의하는 DDL(Data Definition Language) 정보를 담고 있습니다. 이는 각 테이블의 생성 정보와 구조, 필드 속성 등을 포함하여 쿼리를 작성할 때 데이터베이스 구조를 이해할 수 있도록 도와줍니다.
- 테이블 Meta : 테이블 메타데이터를 포함하고 있으며, 각 테이블에 대한 상세 설명, 테이블 간 관계 정보, 데이터의 유형과 속성 등 추가적인 메타 정보를 제공합니다.
- 비즈니스 용어 사전 : 우아한형제들 비즈니스에 특화된 용어와 그 정의를 포함하고 있습니다. 예를 들어, 특정 메뉴나 카테고리 용어, 비즈니스에서 자주 사용하는 KPI 등이 정의되어 있어, 비즈니스 용어가 포함된 질문에 대해 LLM이 정확한 의미를 이해할 수 있도록 지원합니다.
- SQL Few Shot : 예시 쿼리와 그에 대한 답변을 담고 있습니다. 이를 통해 LLM이 예시 질문과 답변을 참고하여 적절한 SQL 쿼리를 작성할 수 있게 됩니다.
- Log 사전 : 이 내용에 대해서는 잘 모르겠네요 ㅎㅎ;
2. 분류기(Router Supervisor)를 두어 꼭 필요한 정보에 접근하게 할것.
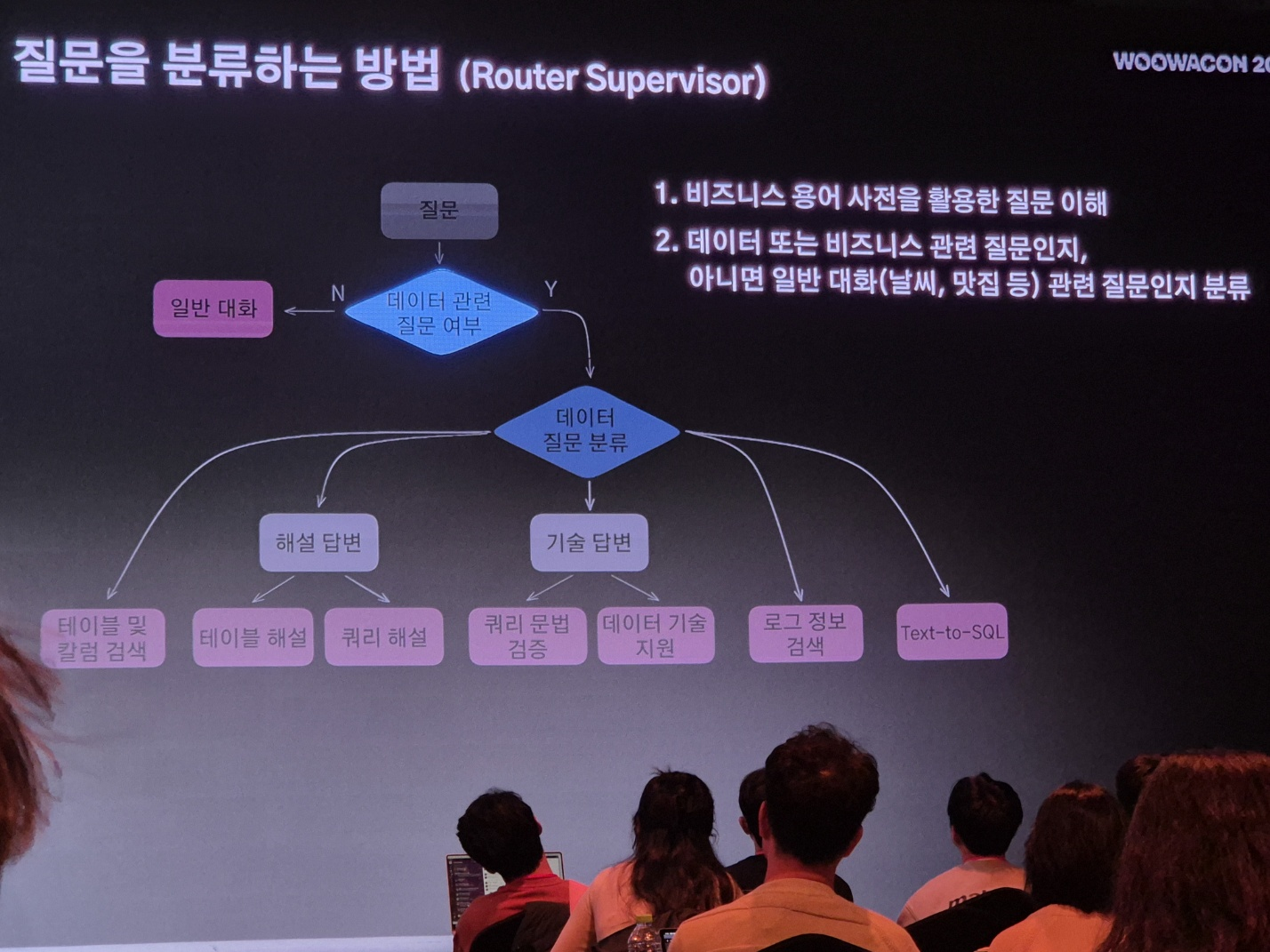
우아한형제들은 내부에서 데이터 질문을 보다 똑똑하게 처리하기 위해 Router Supervisor를 활용해 질문을 분류하고 있습니다. 이 과정은 질문을 목적에 맞게 분해하여 각 VectorDB에 전달하고, 최종적으로 LLM을 통해 답변을 생성하는 구조로 이루어져 있습니다.
1. Router Supervisor로 질문 분류
사용자가 입력한 질문이 들어오면, Router Supervisor는 질문의 성격을 파악하여 크게 두 가지로 분류합니다.
- 일반 대화: 데이터와 관련 없는 날씨나 맛집 추천 등의 대화형 질문은 일반 대화로 분류되어 별도의 응답 경로로 전달됩니다.
- 데이터 관련 질문: 비즈니스 용어 사전을 참고하여 비즈니스 혹은 데이터와 관련된 질문인지를 파악하고, 그에 따라 데이터 질문으로 분류합니다.
2. 데이터 질문 세부 분류
데이터 질문으로 분류된 경우, 질문의 성격에 따라 해설 답변과 기술 답변으로 나누어집니다.
- 해설 답변: 테이블 및 칼럼 검색, 테이블 해설, 쿼리 해설과 같은 설명이 필요한 질문을 처리합니다.
- 기술 답변: 쿼리 문법 검증, 데이터 기술 지원, 로그 정보 검색, Text-to-SQL과 같은 기술적 처리가 필요한 질문을 다룹니다.
3. RAG와 Prompting을 통한 답변 생성
질문이 적절히 분류된 후, RAG (Retrieval Augmented Generation) 방식을 사용해 필요한 정보를 검색하고 결합하여 프롬프트를 생성합니다.
- VectorDB에서 관련 문서 검색: 질문에 맞는 데이터를 각기 다른 VectorDB에서 검색하여 필요한 정보만을 추출합니다.
- 프롬프트 생성: 추출된 문서를 기반으로 여러 프롬프트를 결합하여 LLM이 질문의 맥락을 이해하고 답변을 제공할 수 있도록 합니다.
- LLM을 통한 응답: 최종적으로 LLM은 결합된 프롬프트를 입력받아 사용자의 질문에 맞는 답변을 생성합니다.
3. 다이나믹 프롬프팅 기법을 통한 프롬프트 최적화
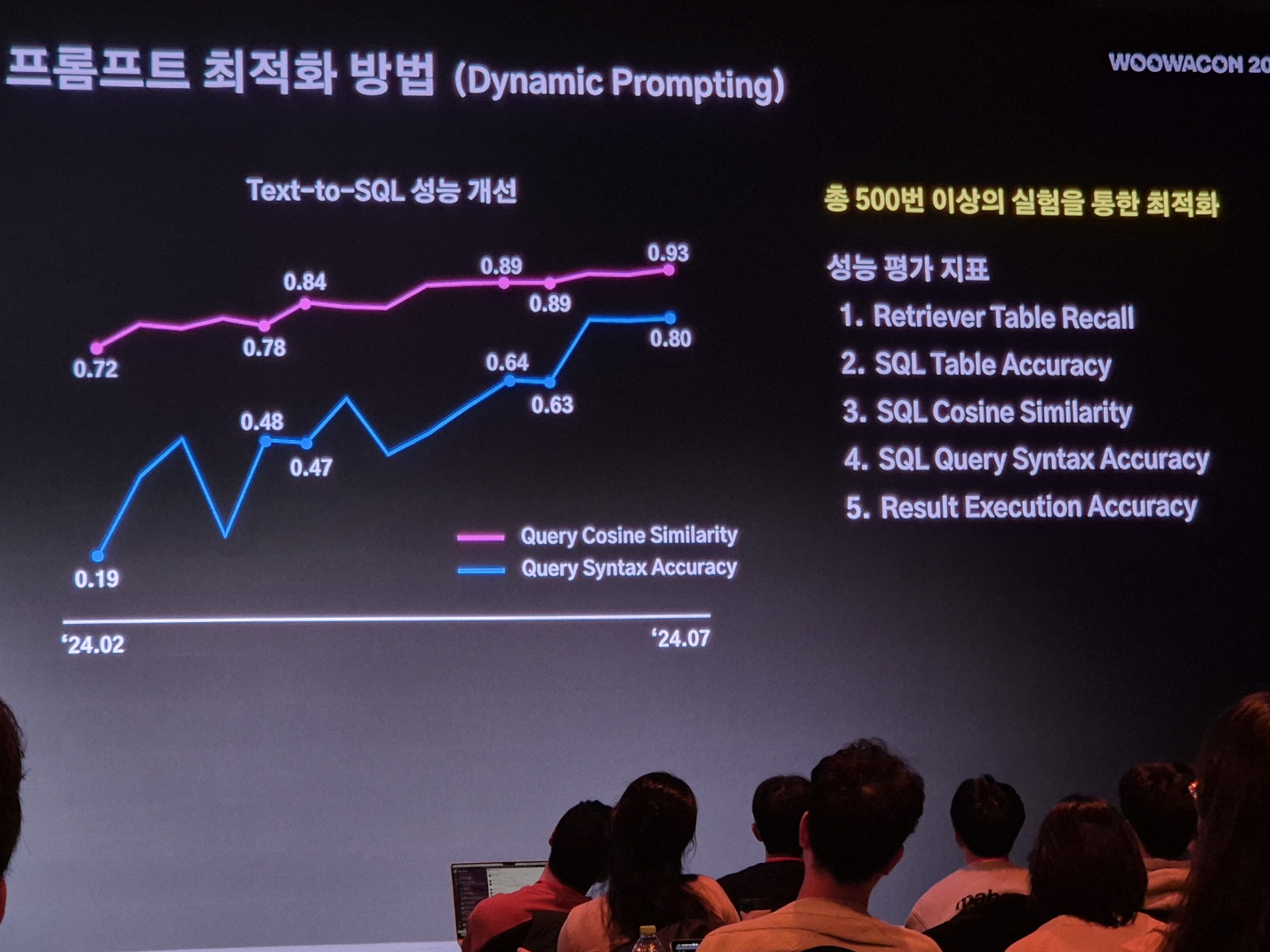

우아한형제들에서 Text-to-SQL 성능을 개선하기 위해 다이나믹 프롬프팅 기법을 적용하여 동적으로 프롬프트를 최적화였습니다.SQL 쿼리의 성능을 평가할 수 있는 다섯 가지 지표를 기준을 만들고 더 높은 점수가 나오는 프롬프트를 찾아가면서 LLM이 프롬프트를 조정하여 더 정확한 쿼리를 생성할 수 있도록 지원합니다.
성능 평가 지표
- Retriever Table Recall: 필요한 테이블을 제대로 찾는 능력
- SQL Table Accuracy: 올바른 테이블을 사용하는 정확성
- SQL Cosine Similarity: 유사한 문맥에서의 SQL 쿼리 유사성
- SQL Query Syntax Accuracy: SQL 문법의 정확성
- Result Execution Accuracy: 실제 실행 결과의 정확성
다이나믹 프롬프팅의 작동 방식
LLM은 질문에 따라 이 성능 지표들을 기준으로 프롬프트를 동적으로 수정합니다. 각 실험에서 SQL 쿼리 성능이 향상될 때마다 LLM이 생성하는 프롬프트는 더 세밀해지고, 쿼리 작성에 필요한 정보가 지속적으로 업데이트됩니다. 실제로 이미지에서 보듯이, 실험이 거듭될수록 Query Cosine Similarity와 Query Syntax Accuracy가 눈에 띄게 향상된 것을 확인할 수 있습니다.
마치며
개인적으로 생성형 AI에 대한 지식이 많진 않기에 더욱 재밌게 다가온 컨퍼런스 발표였습니다. VecterDB를 다중화하고, 각 VecterDB를 목적에 맞게 분리한다는 접근을 상상도 해보지 못하였고, 막연하게 감각적으로 이런 내용이 필요하고 이렇게 접근하면 좋겠네~ 하는 것들을 구조화한것이 저에게는 매우 인상적이였습니다. 그래서 이번 발표는 생성형 AI와 데이터 처리에 대한 새로운 통찰을 제공해준 소중한 경험이 될 것 같습니다.
'Conference' 카테고리의 다른 글
| 2024 WOOWACON에서 발표했던 뒤늦은 후기 (0) | 2024.12.16 |
|---|---|
| 모두팝 세미나 - A Unified Framework to Calculate Every Deep Learning Architecture by Hand 리뷰 (1) | 2024.07.10 |
| 모두의 연구소 방문 후기 (0) | 2024.02.12 |
| Tech Talk - 생성 AI시장의 발전과 혁신 (8) | 2023.11.13 |